zelig-relogit¶
Rare Events Logistic Regression for Dichotomous Dependent Variables
The relogit procedure estimates the same model as standard logistic regression (appropriate when you have a dichotomous dependent variable and a set of explanatory variables; see ), but the estimates are corrected for the bias that occurs when the sample is small or the observed events are rare (i.e., if the dependent variable has many more 1s than 0s or the reverse). The relogit procedure also optionally uses prior correction for case-control sampling designs.
Syntax¶
With reference classes:
z5 <- zrelogit$new()
z5$zelig(Y ~ X1 + X2, tau = NULL,
case.control = c("prior", "weighting"),
bias.correct = TRUE,
data = mydata, ...)
z5$setx()
z5$sim()
With the Zelig 4 compatibility wrappers:
z.out <- zelig(Y ~ X1 + X2, model = "relogit", tau = NULL,
case.control = c("prior", "weighting"),
bias.correct = TRUE,
data = mydata, ...)
x.out <- setx(z.out)
s.out <- sim(z.out, x = x.out)
Arguments¶
The relogit procedure supports four optional arguments in addition to the standard arguments for zelig(). You may additionally use:
- tau: a vector containing either one or two values for , the true population fraction of ones. Use, for example, tau = c(0.05, 0.1) to specify that the lower bound on tau is 0.05 and the upper bound is 0.1. If left unspecified, only finite-sample bias correction is performed, not case-control correction.
- case.control: if tau is specified, choose a method to correct for case-control sampling design: “prior” (default) or “weighting”.
- bias.correct: a logical value of TRUE (default) or FALSE indicating whether the intercept should be corrected for finite sample (rare events) bias.
Note that if tau = NULL, bias.correct = FALSE, the relogit procedure performs a standard logistic regression without any correction.
Example 1: One Tau with Prior Correction and Bias Correction¶
Due to memory and space considerations, the data used here are a sample drawn from the full data set used in King and Zeng, 2001, The proportion of militarized interstate conflicts to the absence of disputes is . To estimate the model,
data(mid)
z.out1 <- zelig(conflict ~ major + contig + power + maxdem + mindem + years,
data = mid, model = "relogit", tau = 1042/303772)
## Warning in readLines(zeligmixedmodels): incomplete final line found on
## '/usr/lib64/R/library/ZeligMultilevel/JSON/zelig5mixedmodels.json'
## How to cite this model in Zelig:
## Christine Choirat, Christopher Gandrud, James Honaker, Kosuke Imai, Gary King, and Olivia Lau. 2017.
## relogit: Rare Events Logistic Regression for Dichotomous Dependent Variables
## in Christine Choirat, Christopher Gandrud, James Honaker, Kosuke Imai, Gary King, and Olivia Lau,
## "Zelig: Everyone's Statistical Software," http://zeligproject.org/
Summarize the model output:
summary(z.out1)
## Model:
##
## Call:
## z5$zelig(formula = conflict ~ major + contig + power + maxdem +
## mindem + years, tau = 1042/303772, data = mid)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -1.067 -0.038 -0.023 2.108 4.458
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) -7.5084 0.1797 -41.79 < 2e-16
## major 2.4320 0.1576 15.44 < 2e-16
## contig 4.1080 0.1577 26.06 < 2e-16
## power 1.0536 0.2172 4.85 1.2e-06
## maxdem 0.0480 0.0101 4.77 1.8e-06
## mindem -0.0641 0.0128 -5.01 5.5e-07
## years -0.0629 0.0057 -11.03 < 2e-16
##
## (Dispersion parameter for binomial family taken to be 1)
##
## Null deviance: 3979.5 on 3125 degrees of freedom
## Residual deviance: 1868.5 on 3119 degrees of freedom
## AIC: 1883
##
## Number of Fisher Scoring iterations: 6
##
## Next step: Use 'setx' method
Set the explanatory variables to their means:
x.out1 <- setx(z.out1)
Simulate quantities of interest:
s.out1 <- sim(z.out1, x = x.out1)
summary(s.out1)
##
## sim x :
## -----
## ev
## mean sd 50% 2.5% 97.5%
## [1,] 0.0024 0.000157 0.00239 0.00212 0.00273
## pv
## 0 1
## [1,] 0.996 0.004
plot(s.out1)
Graphs of Quantities of Interest for Rare Events Logistic Regression
Example 2: One Tau with Weighting, and Bias Correction¶
Suppose that we wish to perform case control correction using weighting (rather than the default prior correction). To estimate the model:
z.out2 <- zelig(conflict ~ major + contig + power + maxdem + mindem + years,
data = mid, model = "relogit", tau = 1042/303772,
case.control = "weighting")
## Warning in readLines(zeligmixedmodels): incomplete final line found on
## '/usr/lib64/R/library/ZeligMultilevel/JSON/zelig5mixedmodels.json'
## How to cite this model in Zelig:
## Christine Choirat, Christopher Gandrud, James Honaker, Kosuke Imai, Gary King, and Olivia Lau. 2017.
## relogit: Rare Events Logistic Regression for Dichotomous Dependent Variables
## in Christine Choirat, Christopher Gandrud, James Honaker, Kosuke Imai, Gary King, and Olivia Lau,
## "Zelig: Everyone's Statistical Software," http://zeligproject.org/
Summarize the model output:
summary(z.out2)
## Model:
##
## Call:
## z5$zelig(formula = conflict ~ major + contig + power + maxdem +
## mindem + years, tau = 1042/303772, case.control = "weighting",
## data = mid)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -1.3600 -0.0705 -0.0351 0.1783 0.4533
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) -5.9746 1.1397 -5.24 1.6e-07
## major 1.6991 0.7738 2.20 0.028
## contig 3.8776 0.7396 5.24 1.6e-07
## power 0.3281 1.0569 0.31 0.756
## maxdem 0.0601 0.0509 1.18 0.238
## mindem -0.0474 0.0734 -0.65 0.519
## years -0.0963 0.0471 -2.05 0.041
##
## (Dispersion parameter for binomial family taken to be 1)
##
## Null deviance: 143.116 on 3125 degrees of freedom
## Residual deviance: 91.178 on 3119 degrees of freedom
## AIC: 27.04
##
## Number of Fisher Scoring iterations: 10
##
## Next step: Use 'setx' method
Set the explanatory variables to their means:
x.out2 <- setx(z.out2)
Simulate quantities of interest:
s.out2 <- sim(z.out2, x = x.out2)
summary(s.out2)
##
## sim x :
## -----
## ev
## mean sd 50% 2.5% 97.5%
## [1,] 0.00494 0.00284 0.00419 0.0014 0.0122
## pv
## 0 1
## [1,] 0.993 0.007
Example 3: Two Taus with Bias Correction and Prior Correction¶
Suppose that we did not know that , but only that it was somewhere between . To estimate a model with a range of feasible estimates for (using the default prior correction method for case control correction):
z.out2 <- zelig(conflict ~ major + contig + power + maxdem + mindem + years, data = mid, model = "relogit", tau = c(0.002, 0.005))
## Warning in readLines(zeligmixedmodels): incomplete final line found on
## '/usr/lib64/R/library/ZeligMultilevel/JSON/zelig5mixedmodels.json'
## How to cite this model in Zelig:
## Christine Choirat, Christopher Gandrud, James Honaker, Kosuke Imai, Gary King, and Olivia Lau. 2017.
## relogit: Rare Events Logistic Regression for Dichotomous Dependent Variables
## in Christine Choirat, Christopher Gandrud, James Honaker, Kosuke Imai, Gary King, and Olivia Lau,
## "Zelig: Everyone's Statistical Software," http://zeligproject.org/
Summarize the model output:
z.out2
## Model:
## Warning in summary.default(.$z.out): number of items to replace is not a
## multiple of replacement length
## Length Class Mode
## lower.estimate 35 Relogit list
## upper.estimate 35 Relogit list
## formula 1 Formula call
## Next step: Use 'setx' method
Set the explanatory variables to their means:
x.out2 <- setx(z.out2)
Simulate quantities of interest:
s.out <- sim(z.out2, x = x.out2)
## Error in UseMethod("vcov"): no applicable method for 'vcov' applied to an object of class "c('Relogit2', 'Relogit')"
summary(s.out2)
##
## sim x :
## -----
## ev
## mean sd 50% 2.5% 97.5%
## [1,] 0.00494 0.00284 0.00419 0.0014 0.0122
## pv
## 0 1
## [1,] 0.993 0.007
plot(s.out2)
Graphs of Quantities of Interest for Rare Events Logistic Regression
The cost of giving a range of values for is that point estimates are not available for quantities of interest. Instead, quantities are presented as confidence intervals with significance less than or equal to a specified level (e.g., at least 95% of the simulations are contained in the nominal 95% confidence interval).
Model¶
Like the standard logistic regression, the stochastic component for the rare events logistic regression is:
where is the binary dependent variable, and takes a value of either 0 or 1.
The systematic component is:
If the sample is generated via a case-control (or choice-based) design, such as when drawing all events (or “cases”) and a sample from the non-events (or “controls”) and going backwards to collect the explanatory variables, you must correct for selecting on the dependent variable. While the slope coefficients are approximately unbiased, the constant term may be significantly biased. Zelig has two methods for case control correction:
The “prior correction” method adjusts the intercept term. Let be the true population fraction of events, the fraction of events in the sample, and the uncorrected intercept term. The corrected intercept is:
The “weighting” method performs a weighted logistic regression to correct for a case-control sampling design. Let the 1 subscript denote observations for which the dependent variable is observed as a 1, and the 0 subscript denote observations for which the dependent variable is observed as a 0. Then the vector of weights
If is unknown, you may alternatively specify an upper and lower bound for the possible range of . In this case, the relogit procedure uses “robust Bayesian” methods to generate a confidence interval (rather than a point estimate) for each quantity of interest. The nominal coverage of the confidence interval is at least as great as the actual coverage.
By default, estimates of the the coefficients
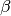 are
bias-corrected to account for finite sample or rare events bias. In
addition, quantities of interest, such as predicted probabilities,
are also corrected of rare-events bias. If
are the uncorrected logit coefficients and
bias() is the bias term, the corrected
coefficients are
are
bias-corrected to account for finite sample or rare events bias. In
addition, quantities of interest, such as predicted probabilities,
are also corrected of rare-events bias. If
are the uncorrected logit coefficients and
bias() is the bias term, the corrected
coefficients areThe bias term is
where
where and are given in the “weighting” section above.
Quantities of Interest¶
For either one or no :
The expected values (qi$ev) for the rare events logit are simulations of the predicted probability
given draws of
from its posterior.The predicted value (qi$pr) is a draw from a binomial distribution with mean equal to the simulated .
The first difference (qi$fd) is defined as
The risk ratio (qi$rr) is defined as
For a range of defined by , each of the quantities of interest are matrices, which report the lower and upper bounds, respectively, for a confidence interval with nominal coverage at least as great as the actual coverage. At worst, these bounds are conservative estimates for the likely range for each quantity of interest. Please refer to for the specific method of calculating bounded quantities of interest.
In conditional prediction models, the average expected treatment effect (att.ev) for the treatment group is
where is a binary explanatory variable defining the treatment () and control () groups. Variation in the simulations are due to uncertainty in simulating , the counterfactual expected value of for observations in the treatment group, under the assumption that everything stays the same except that the treatment indicator is switched to .
In conditional prediction models, the average predicted treatment effect (att.pr) for the treatment group is
where is a binary explanatory variable defining the treatment () and control () groups. Variation in the simulations are due to uncertainty in simulating , the counterfactual predicted value of for observations in the treatment group, under the assumption that everything stays the same except that the treatment indicator is switched to .
Output Values¶
The Zelig object stores fields containing everything needed to rerun the Zelig output, and all the results and simulations as they are generated. In addition to the summary commands demonstrated above, some simply utility functions (known as getters) provide easy access to the raw fields most commonly of use for further investigation.
In the example above z.out1$getcoef() returns the estimated coefficients, z.out1$getvcov() returns the estimated covariance matrix, and z.out1$getpredict() provides predicted values for all observations in the dataset from the analysis.
Differences with Stata Version¶
The Stata version of ReLogit and the R implementation differ slightly in their coefficient estimates due to differences in the matrix inversion routines implemented in R and Stata. Zelig uses orthogonal-triangular decomposition (through lm.influence()) to compute the bias term, which is more numerically stable than standard matrix calculations.
See also¶
King G and Zeng L (2001). “Logistic Regression in Rare Events Data.” Political Analysis, 9 (2), pp. 137-163.
King G and Zeng L (2001). “Explaining Rare Events in International Relations.” International Organization, 55 (3), pp. 693-715.