zelig-lsmixed¶
ls.mixed: Mixed effects Linear Regression
Use multi-level linear regression if you have covariates that are grouped according to one or more classification factors and a continuous dependent variable.
While generally called multi-level models in the social sciences, this class of models is often referred to as mixed-effects models in the statistics literature and as hierarchical models in a Bayesian setting. This general class of models consists of linear models that are expressed as a function of both fixed effects, parameters corresponding to an entire population or certain repeatable levels of experimental factors, and random effects, parameters corresponding to individual experimental units drawn at random from a population.
Syntax¶
z5 <- zlsmixed$new()
z5$zelig(formula= y ~ x1 + x2 + (z1 + z2 | g), weights = w, data = mydata)
z5$setx()
z5$sim()
With the Zelig 4 compatibility wrappers:
z.out <- zelig(formula= y ~ x1 + x2 + (z1 + z2 | g),
data = mydata, weights = w, model = "ls.mixed")
x.out <- setx(z.out)
s.out <- sim(z.out, x = x.out)
Inputs¶
zelig() takes the following arguments for multi:
- formula: a two-sided linear formula object describing the systematic component of the model, with the response on the left of a operator and the fixed effects terms, separated by + operators, on the right. Any random effects terms are included with the notation (z1 + ... + zn | g) with z1 + ... + zn specifying the model for the random effects and g the grouping structure. Random intercept terms are included with the notation (1 | g).
Additional Inputs¶
Additionally, users may wish to refer to lmer in the package lme4 for more information, including control parameters for the estimation algorithm and their defaults.
Examples¶
Basic Example with First Differences¶
Attach sample data:
data(voteincome)
Estimate model:
z.out <- zelig(income ~ education + age + female + (1 | state),
data = voteincome, model = "ls.mixed")
Summarize regression coefficients and estimated variance of random effects:
summary(z.out)
Set explanatory variables to their default values, with high (80th percentile) and low (20th percentile) values for education:
x.high <- setx(z.out, education=quantile(voteincome$education, 0.8))
x.low <- setx(z.out, education=quantile(voteincome$education, 0.2))
Generate first differences for the effect of high versus low education on income:
s.out <- sim(z.out, x = x.high, x1 = x.low)
summary(s.out)
plot(s.out)
Mixed effects linear regression model¶
Let be the continuous dependent variable, realized for
observation in group 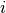 as , for
, .
as , for
, .
The stochastic component is described by a univariate normal model with a vector of means and scalar variance .
The -dimensional vector of random effects, , is restricted to be mean zero, and therefore is completely characterized by the variance covarance matrix , a symmetric positive semi-definite matrix.
The systematic component is
where is the array of known fixed effects explanatory variables,
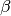 is the
-dimensional vector of fixed effects coefficients,
is the array of known
random effects explanatory variables and is the
-dimensional vector of random effects.
is the
-dimensional vector of fixed effects coefficients,
is the array of known
random effects explanatory variables and is the
-dimensional vector of random effects.
Quantities of Interest¶
The predicted values (qi$pr) are draws from the normal distribution defined by mean and variance ,
given and and simulations of
and from their posterior distributions. The
estimated variance covariance matrices are taken as correct and are
themselves not simulated.The expected values (qi$ev) are averaged over the stochastic components and are given by
The first difference (qi$fd) is given by the difference in expected values, conditional on and , representing different values of the explanatory variables.
In conditional prediction models, the average predicted treatment effect (qi$att.pr) for the treatment group is given by
where is a binary explanatory variable defining the treatment and control groups. Variation in the simulations is due to uncertainty in simulating , the counterfactual predicted value of for observations in the treatment group, under the assumption that everything stays the same except that the treatment indicator is switched to .
In conditional prediction models, the average expected treatment effect (qi$att.ev) for the treatment group is given by
where is a binary explanatory variable defining the treatment and control groups. Variation in the simulations is due to uncertainty in simulating , the counterfactual expected value of for observations in the treatment group, under the assumption that everything stays the same except that the treatment indicator is switched to .
If “log” link is used, expected values are computed as above and then exponentiated, while predicted values are draws from the log-normal distribution whose logarithm has mean and variance equal to and , respectively.
Output Values¶
The output of each Zelig command contains useful information which you may view. You may examine the available information in z.out by using slotNames(z.out), see the fixed effect coefficients by using summary(z.out)@coefs, and a default summary of information through summary(z.out). Other elements available through the operator are listed below.
- From the zelig() output stored in summary(z.out), you may extract:
- fixef: numeric vector containing the conditional estimates of the fixed effects.
- ranef: numeric vector containing the conditional modes of the random effects.
- frame: the model frame for the model.
- From the sim() output stored in s.out, you may extract quantities of
interest stored in a data frame:
- qi$pr: the simulated predicted values drawn from the distributions defined by the expected values.
- qi$ev: the simulated expected values for the specified values of x.
- qi$fd: the simulated first differences in the expected values for the values specified in x and x1.
- qi$ate.pr: the simulated average predicted treatment effect for the treated from conditional prediction models.
- qi$ate.ev: the simulated average expected treatment effect for the treated from conditional prediction models.
See also¶
Mixed effects linear regression is part of lme4 package.
## Error in eval(expr, envir, enclos): object 'zlsmixed' not found
R Core Team (2017). R: A Language and Environment for Statistical Computing. R Foundation for Statistical Computing, Vienna, Austria. <URL: https://www.R-project.org/>.