Warning
ZeligMultilevel is currently under development. We are working on the model vignettes of the package.
zeligmultilevel-gammamixed¶
gamma.mixed: Mixed effects gamma regression
Use generalized multi-level linear regression if you have covariates that are grouped according to one or more classification factors. Gamma regression models a continuous, positive dependent variable.
While generally called multi-level models in the social sciences, this class of models is often referred to as mixed-effects models in the statistics literature and as hierarchical models in a Bayesian setting. This general class of models consists of linear models that are expressed as a function of both fixed effects, parameters corresponding to an entire population or certain repeatable levels of experimental factors, and random effects, parameters corresponding to individual experimental units drawn at random from a population.
Syntax¶
z5 <- zgammamixed$new()
z5$zelig(formula= y ~ x1 + x2 + (z1 + z2 | g), weights = w, data = mydata)
z5$setx()
z5$sim()
With the Zelig 4 compatibility wrappers:
z.out <- zelig(formula= y ~ x1 + x2 + (z1 + z2 | g),
data = mydata, weights = w, model = "gamma.mixed")
x.out <- setx(z.out)
s.out <- sim(z.out, x = x.out)
Inputs¶
takes the following arguments for mixed:
- formula: a two-sided linear formula object describing the systematic component of the model, with the response on the left of a operator and the fixed effects terms, separated by + operators, on the right. Any random effects terms are included with the notation (z1 + ... + zn | g) with z1 + ... + zn specifying the model for the random effects and g the grouping structure. Random intercept terms are included with the notation (1 | g). | Alternatively, formula may be a list where the first entry, mu, is a two-sided linear formula object describing the systematic component of the model, with the repsonse on the left of a operator and the fixed effects terms, separated by + operators, on the right. Any random effects terms are included with the notation (z1, delta | g) with z1 specifying the individual level model for the random effects, g the grouping structure and delta references the second equation in the list. The delta equation is one-sided linear formula object with the group level model for the random effects on the right side of a operator. The model is specified with the notation (w1 + ... + wn | g) with w1 + ... + wn specifying the group level model and g the grouping structure.
Additional Inputs¶
In addition, zelig() accepts the following additional arguments for model specification:
- data: An optional data frame containing the variables named in formula. By default, the variables are taken from the environment from which zelig() is called.
- method: a character string. The criterion is always the log-likelihood but this criterion does not have a closed form expression and must be approximated. The default approximation is “PQL” or penalized quasi-likelihood. Alternatives are “Laplace” or “AGQ” indicating the Laplacian and adaptive Gaussian quadrature approximations respectively.
- na.action: A function that indicates what should happen when the data contain NAs. The default action (na.fail) causes zelig() to print an error message and terminate if there are any incomplete observations.
Additionally, users may with to refer to lmer in the package lme4 for more information, including control parameters for the estimation algorithm and their defaults.
Examples¶
Basic Example with First Differences¶
Attach sample data:
data(coalition2)
Estimate model using optional arguments to specify approximation method for the log-likelihood, and the log link function for the Gamma family:
z.out1 <- zelig(duration ~ invest + fract + polar + numst2 + crisis + (1 | country),
data=coalition2, model = "gamma.mixed")
## Warning in readLines(zeligmixedmodels): incomplete final line found on
## '/usr/lib64/R/library/ZeligMultilevel/JSON/zelig5mixedmodels.json'
## Warning in checkConv(attr(opt, "derivs"), opt$par, ctrl =
## control$checkConv, : Model failed to converge with max|grad| = 0.00475129
## (tol = 0.001, component 1)
## Warning in checkConv(attr(opt, "derivs"), opt$par, ctrl = control$checkConv, : Model is nearly unidentifiable: very large eigenvalue
## - Rescale variables?;Model is nearly unidentifiable: large eigenvalue ratio
## - Rescale variables?
## How to cite this model in Zelig:
## TBD. 2016.
## gamma.mixed:
## in Christine Choirat, James Honaker, Kosuke Imai, Gary King, and Olivia Lau,
## "Zelig: Everyone's Statistical Software," http://zeligproject.org/
Summarize regression coefficients and estimated variance of random effects:
summary(z.out1)
## Model:
## Generalized linear mixed model fit by maximum likelihood (Laplace
## Approximation) [glmerMod]
## Family: Gamma ( log )
## Formula:
## duration ~ invest + fract + polar + numst2 + crisis + (1 | country)
## Data: coalition2
##
## AIC BIC logLik deviance df.resid
## 2296 2325 -1140 2280 296
##
## Scaled residuals:
## Min 1Q Median 3Q Max
## -1.315 -0.806 -0.204 0.625 4.615
##
## Random effects:
## Groups Name Variance Std.Dev.
## country (Intercept) 0.0298 0.173
## Residual 0.5291 0.727
## Number of obs: 304, groups: country, 14
##
## Fixed effects:
## Estimate Std. Error t value Pr(>|z|)
## (Intercept) 3.607104 0.567011 6.36 2.0e-10
## invest -0.380086 0.164914 -2.30 0.02118
## fract -0.000853 0.000830 -1.03 0.30410
## polar -0.024542 0.007102 -3.46 0.00055
## numst2 0.457154 0.106965 4.27 1.9e-05
## crisis 0.003178 0.001467 2.17 0.03029
##
## Correlation of Fixed Effects:
## (Intr) invest fract polar numst2
## invest -0.152
## fract -0.971 0.084
## polar 0.391 -0.315 -0.500
## numst2 -0.254 -0.065 0.138 0.051
## crisis 0.141 0.011 -0.168 -0.060 -0.112
## convergence code: 0
## Model failed to converge with max|grad| = 0.00475129 (tol = 0.001, component 1)
## Model is nearly unidentifiable: very large eigenvalue
## - Rescale variables?
## Model is nearly unidentifiable: large eigenvalue ratio
## - Rescale variables?
##
## Next step: Use 'setx' method
Set the baseline values (with the ruling coalition in the minority) and the alternative values (with the ruling coalition in the majority) for X:
x.high <- setx(z.out1, numst2 = 1)
## [1] "country"
x.low <- setx(z.out1, numst2 = 0)
## [1] "country"
Simulate expected values and first differences:
##
## sim x :
## -----
## ev
## mean sd 50% 2.5% 97.5%
## [1,] 1.4 0.0163 1.4 1.37 1.43
## pv
## mean sd 50% 2.5% 97.5%
## [1,] 1.02 0.822 0.804 0.0706 3.05
##
## sim x1 :
## -----
## ev
## mean sd 50% 2.5% 97.5%
## [1,] 1.49 0.0275 1.49 1.44 1.54
## pv
## mean sd 50% 2.5% 97.5%
## [1,] 1.12 0.918 0.873 0.0842 3.55
## fd
## mean sd 50% 2.5% 97.5%
## [1,] 0.0884 0.0262 0.0881 0.04 0.144
s.out1 <- sim(z.out1, x = x.high, x1 = x.low)
summary(s.out1)
plot(s.out1)
Graphs of Quantities of Interest for Gamma Mixed Model
Mixed effects gamma regression Model¶
Let be the continuous, positive dependent variable,
realized for observation in group 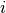 as ,
for , .
as ,
for , .
The stochastic component is described by a Gamma model with scale parameter
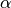 .
.where
for 0"/>.
The -dimensional vector of random effects, , is restricted to be mean zero, and therefore is completely characterized by the variance covarance matrix , a symmetric positive semi-definite matrix.
The systematic component is
where is the array of known fixed effects explanatory variables,
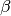 is the
-dimensional vector of fixed effects coefficients,
is the array of known
random effects explanatory variables and is the
-dimensional vector of random effects.
is the
-dimensional vector of fixed effects coefficients,
is the array of known
random effects explanatory variables and is the
-dimensional vector of random effects.
Quantities of Interest¶
The predicted values are draws from the gamma distribution for each given set of parameters , for
given and and simulations of of
and from their posterior distributions. The
estimated variance covariance matrices are taken as correct and are
themselves not simulated.The expected values (qi$ev) are simulations of the mean of the stochastic component given draws of
,
from their posteriors:The first difference (qi$fd) is given by the difference in expected values, conditional on and , representing different values of the explanatory variables.
In conditional prediction models, the average predicted treatment effect (qi$att.pr) for the treatment group is given by
where is a binary explanatory variable defining the treatment and control groups. Variation in the simulations is due to uncertainty in simulating , the counterfactual predicted value of for observations in the treatment group, under the assumption that everything stays the same except that the treatment indicator is switched to .
In conditional prediction models, the average expected treatment effect (qi$att.ev) for the treatment group is given by
where is a binary explanatory variable defining the treatment and control groups. Variation in the simulations is due to uncertainty in simulating , the counterfactual expected value of for observations in the treatment group, under the assumption that everything stays the same except that the treatment indicator is switched to .
Output Values¶
The output of each Zelig command contains useful information which you may view. You may examine the available information in z.out by using getters (http://docs.zeligproject.org/en/latest/getters.html), see the fixed effect coefficients by using z.out$getcoef(), and a default summary of information through summary(z.out). Other elements available are listed below.
- From the zelig() output stored in summary(z.out), you may extract:
- fixef: numeric vector containing the conditional estimates of the fixed effects.
- ranef: numeric vector containing the conditional modes of the random effects.
- From the sim() output stored in s.out, you may extract quantities of
interest via getters:
- s.out$getqi(qi = "pv"): the simulated predicted values drawn from the distributions defined by the expected values.
- s.out$getqi(qi = "ev"): the simulated expected values for the specified values of x.
- s.out$getqi(qi = "fd"): the simulated first differences in the expected values for the values specified in x and x1.
- s.out$getqi(treatment): the simulated average predicted treatment effect for the treated from conditional prediction models.
See also¶
Mixed effects gamma regression is part of lme4 package.
Bates D, Mächler M, Bolker B and Walker S (2015). “Fitting Linear Mixed-Effects Models Using lme4.” Journal of Statistical Software, 67 (1), pp. 1-48. doi: 10.18637/jss.v067.i01 (URL: http://doi.org/10.18637/jss.v067.i01).